Origin Stories
Personalised AI-generated comic videos for a dog adoption campaign — using narrative structure to solve early Sora's technical constraints.
Most early Sora explorations went looking for what the model could do. I got more interested in what it structurally couldn't — and whether that pointed somewhere.
When our team got access to the Sora API on Azure OpenAI in early 2025 — among the first through WPP — testing quickly surfaced the limits: no image input, and multi-subject consistency that broke across scenes. The standard response would have been to work around it — tighter prompting, post-processing, reduced scope. Instead, I treated the constraint as a design brief: what narrative form is native to this?
Comics. Not as a compromise, but as the right answer — a format where each panel isolates one subject, one moment, and the reader's mind constructs continuity in the gaps. Scott McCloud calls it closure: the invisible story that happens in the gutter. The model's limitation became structurally irrelevant.
That reframe shaped everything that followed.
Hands-on passes also highlighted strengths we could lean on — striking stylisation and unusual aspect ratios — even while identity across clips stayed brittle when a story had to carry multiple subjects across scenes. In our prototype, that showed up as the same dog needing to read as the same animal from panel to panel.
The brief took shape from there: a personalised adoption campaign for a dog food brand, where users upload a photo of their dog and receive a fully customised comic-style video — the dog as the protagonist, the owner as the hero, the story ending with a thank-you to the adopter.
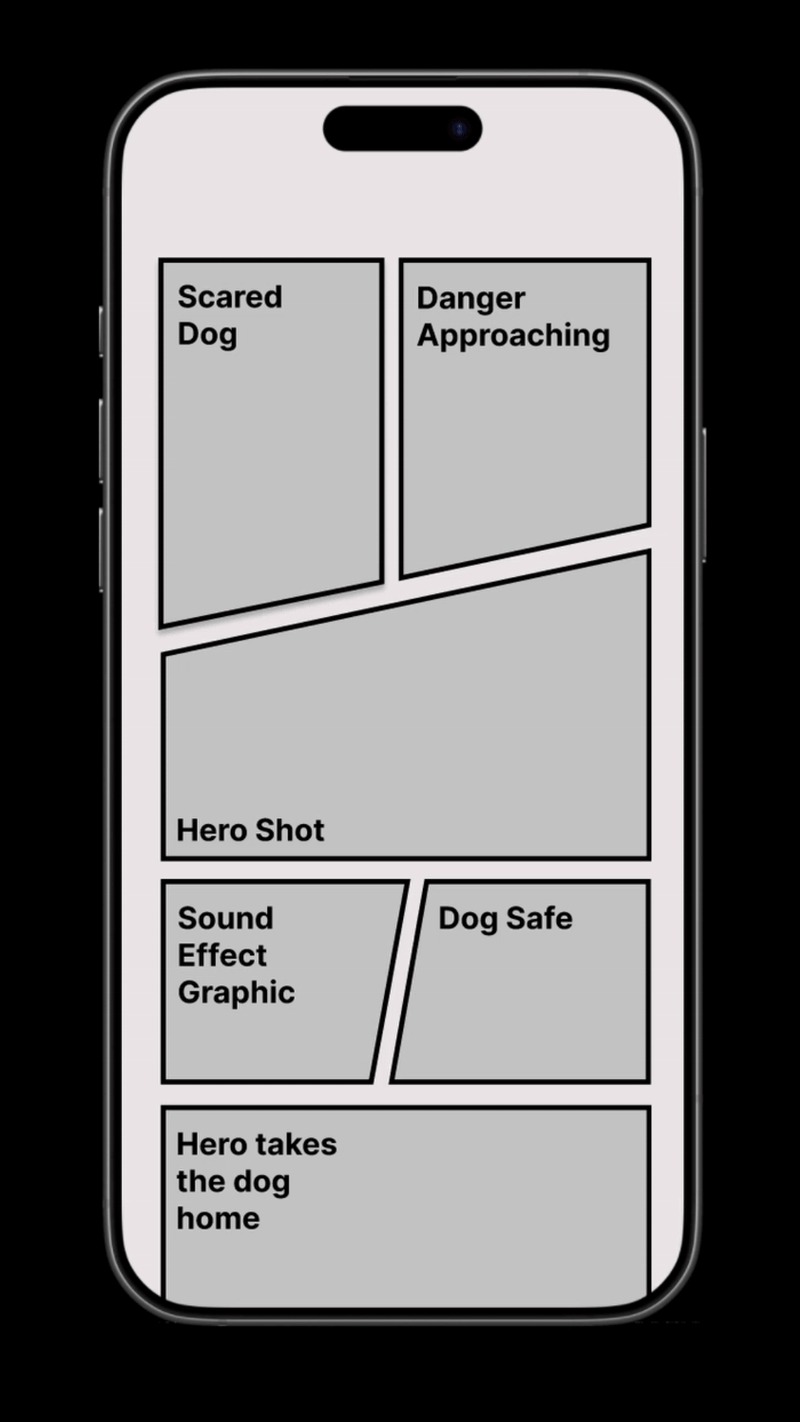
The workflow
- GPT-4 series models analysed uploaded pet and owner photos to generate scene-specific descriptions — one per panel, scoped to its narrative beat
- Six panels with fixed beats: environment establishing, scared dog, danger approaching, hero shot, dog safe, hero takes the dog home — closing with a personalised thank-you message to the adopter
- Each panel generated as an independent short video clip through Sora on Azure OpenAI — subject isolation per panel ensured consistency and stability across the full sequence
- Clips cropped and assembled into the comic layout; Figma for panel composition and layout design, After Effects templates for final assembly and delivery
The full pipeline ran from initial exploration to prototype delivery in about a week. The team iterated on implementation together once the narrative and panel structure were set.
Prompt excerpts
Meta-prompt and per-panel instructions from the build — click any card to expand.
GPT prompt · system (alternate attempt)
GPT Prompt alternate attempt: You are a language model with the purpose of writing text-to-video prompts in a Golden Age comic book style. This style must maintain consistency across all prompts and include the following: Bold black outlines, halftone textures, and saturated vintage colors (with an emphasis on golden-orange sunset tones). A slightly jittery stop-motion effect to enhance motion and dynamism. You will be given the description and image of a dog from an adoption profile as well as the image of the person adopting and must describe extracted information from these assets to apply individually to each of the prompts. Every prompt creates a separate video so they must describe the necessary information within that prompt without relying on the information from the previous prompt. For each prompt: Ensure the dog and person retain consistent physical features, proportions, and markings across all scenes. Apply the comic book aesthetic to all elements, including characters, backgrounds, and text effects. Focus on movement by describing actions that feel alive—such as flowing hair, wagging tails, barking, running, flying, spinning, or objects interacting dynamically with the environment. Use dramatic, exaggerated poses and dynamic angles for any actions or movements. For missing context, default to a dark background with golden-orange highlights to emphasize the subject. Generate individual prompts based on the given descriptions while adhering strictly to this visual style.
Prompt 1 · Scared dog
Prompt 1 - Take the provided image of the dog describe its colour, hair length, size, breed and markings and use that to describe a prompt for image generation that shows this dog trembling with a frightened expression. The dog is walking slowly against a dark fill colour background, just highlighting the dog's features.
Prompt 2 · Environment establishing
Prompt 2 - Take the provided image of the dog describe its colour, hair length, size, breed and markings. We see the dog walking in the setting the dog was in prior to rescue, find this information from the provided text document. However if this information is not available, default to a visual of the dog barking.
Prompt 3 · Danger approaching (WHOOSH)
Prompt 3 - Describe a prompt that generates a comic book style text field with the words WHOOSH!, that spin in and out of frame.
Prompt 4 · Hero shot
Prompt 4 - Using the person image provided to describe, hair colour, hair style ,skin tone, if they have glasses or not and clothing to generate the prompt of them flying through the sky as a superhero, maintaining the comic book visual style described.
Prompt 5 · Dog safe
Prompt 5 - Take the provided image of the dog describe its colour, hair length, size, breed and markings to describe the dog in the same comic visual style described. The dog is stood looking up with an excited expression. The background has a soft orange glow and the dog has a sparkle in its eyes.
Prompt 6 · Thank-you (closing)
Prompt 6 - Take the {NAME} from the uploaded file {PERSON_NAME.JPG) and the {DOGNAME} from the uploaded file {DOG_DOGNAME.txt}. In keeping with the described visual style a graphic text bubble appears on screen with bold text reading 'Thankyou {NAME} for adopting {DOGNAME}!
Contributions
Set up tools and API access, identified technical constraints through testing, proposed the comic-panel approach as the creative solution, designed the narrative framework and panel structure, and translated that into Figma layouts and After Effects assembly templates.
Tech stack
Azure OpenAI · Sora API · GPT-4 · Figma · After Effects